Los servicios GCP son múltiples y uno muy importantes es Google Cloud Storage
Es un servicio de almacenamiento de archivos en línea RESTful para almacenar y acceder a datos en la infraestructura de Google cloud Platform. El servicio combina el rendimiento y la escalabilidad de la nube de Google con capacidades avanzadas de seguridad y uso compartido.
Puedes usar Cloud Storage en una variedad de situaciones, como la entrega de contenido de sitios web, el almacenamiento de datos para archivo y recuperación ante desastres o la distribución de grandes objetos de datos a los usuarios a través de descargas directas.
Cloud Storage es indispensable
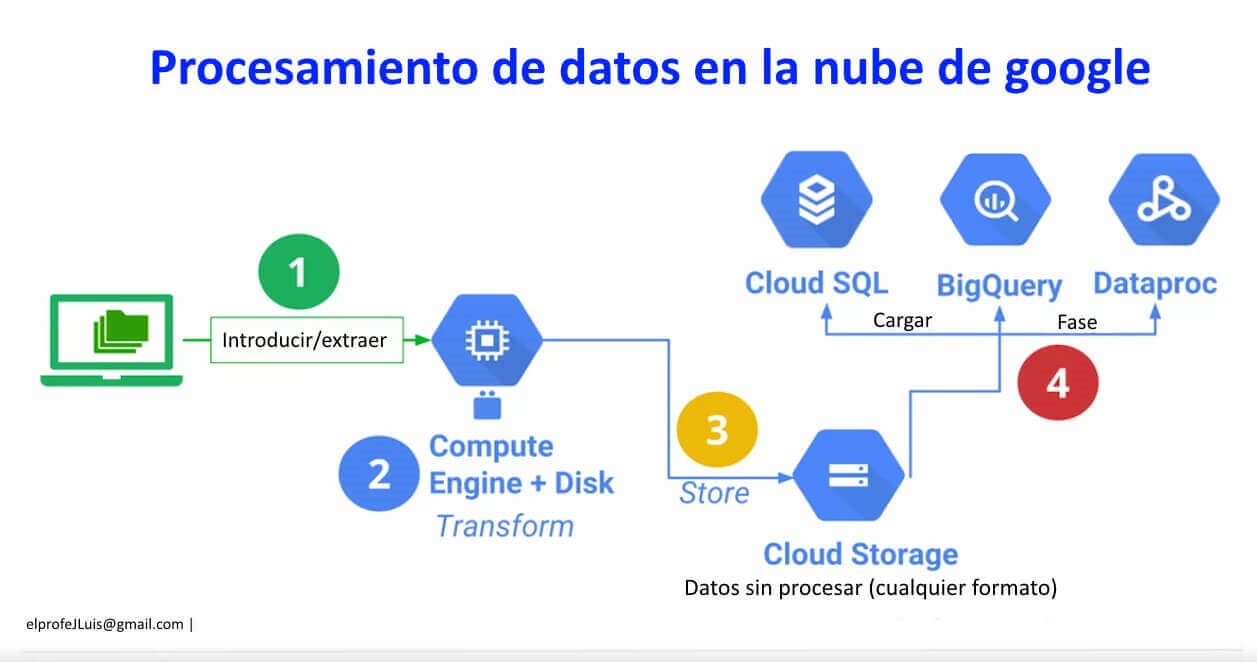
Una de las razones es porque es la etapa intermedia que se debe usar para que los datos de una base de datos relacional, como Cloud SQL se procesen en BigQuery, que es un almacén de datos o en Dataproc, que es un clúster de Hadoop.
Si quieren procesar los datos en GCP primero tienen que estar en Cloud Storage.
Cloud Storage es almacenamiento de BLOB. Se almacenan datos sin procesar en cualquier formato directamente en Cloud Storage.
Para llegar ahí por lo general, se obtienen los datos de otro lugar. Pueden estar en su centro de datos o en instrumentos en el campo o registros que se están creando.
Por lo general, se trata de transferir o extraer datos. Se hace algo de procesamiento que podría ocurrir en Compute Engine. Pueden crear una VM de Compute Engine y harán bastante procesamiento.
Si necesitan hacer procesamiento necesitarán búsquedas, lecturas y escrituras rápidas de los datos, una buena manera de hacerlo es almacenar los datos en un disco, el problema es cuando el motor desaparece, también lo hace el disco.
Cloud Storage es un almacenamiento persistente, es durable y es replicado. Puede estar disponible globalmente, si es necesario y pueden usarlo como etapa intermedia de los datos para otros productos de GCP.
A menudo, el primer paso en el ciclo de vida de los datos es llevarlos a Cloud Storage.
¿Cómo se hace? La forma más simple es usar una herramienta de línea de comandos que se conoce como gsutil.
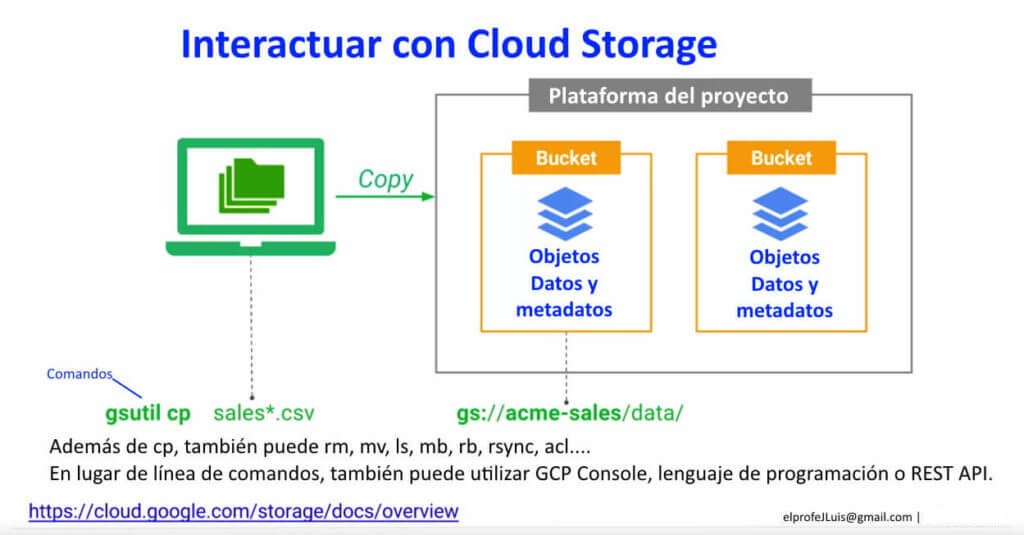
Está incorporado en el SDK de gcloud que pueden instalar y una vez hecho, tendrán la línea de comandos gsutil. Se debe instalar en la máquina desde la que vayan a subir datos. Instalen gcloud, obtengan gsutil y luego hagan la copia con gsutil.
Se hace con «cp». Por ejemplo, «gsutil cp sales*.csv» Ese es un archivo que estoy copiando.
¿Dónde estoy copiando los archivos?
¿Dónde se están copiando?
En este caso, los estoy copiando a Google Storage, eso significa «gs» y le estoy dando una destructuración completa /data y estoy colocando todos los archivos de ventas en /data. Pero en /dataware. Ahí aparece el concepto de depósito.
En general, pueden pensar en un depósito como en un nombre de dominio. Si estuvieran en Internet, las máquinas tienen distintas direcciones y cada una tiene sus propios sistemas de archivos, que son las páginas web.
Los depósitos se parecen mucho a eso. «Acme sales», en este caso, actúa como un nombre de dominio. Es lo que lo hace único, es el depósito. Se puede crear cualquier cantidad de depósitos pero el nombre de depósito debe ser único.
La mayoría de las personas usan un nombre de depósito que tenga relación con el nombre del dominio corporativo. Pueden tener direcciones que coincidan con el nombre de la empresa. Pero si van a usar ese tipo de direcciones GCS dirá: «¿Es usted propietario de ese nombre de empresa?» Y tendrán que probarlo, a través de un cambio en el campo de nombre D, etc. para verificar que son dueños del dominio. Si prueban que son dueños del dominio, obtendrán un nombre de depósito que coincidirá con el nombre del dominio.
Se pueden copiar archivos con «gsutil-cp». Aparte de eso, se pueden quitar con «rm» «mv» es para mover, que es copiarlo y luego borrarlo localmente. Se puede usar «ls» para mostrar una lista de elementos en la nube.
Tomemos en cuenta que esta URL: «gs://acme-sales/data/» aunque lo expliqué como una estructura de carpetas es puramente conveniencia. Simplemente es un nombre de BLOB. Y este nombre es solo una string.
Sin embargo, se tiende a pensar que los sistemas de archivos son jerárquicos y se tiende a pensar lo mismo de GCS. Ahí es donde aparece «ls». Se puede ver la jerarquía. Pero recuerden que esta jerarquía es solo semántica adicional que se usa para un valor clave puro almacenado. También pueden usar «mb» para crear un depósito y «rb» para quitarlo. «rsync», que es una utilidad de Unix, y esta es una emulación de esta utilidad.
Es como un espejo en la nube de un elemento local y cuando se ejecute rsync otra vez verificará los archivos que cambiaron y subirá solo esos archivos. ACL es una lista de control de acceso para cambiar los permisos. Aunque vuelvo a hablar de gsutil como herramienta de línea de comandos no es necesario usarla como línea de comandos porque lo que hace la línea de comandos es invocar un servicio web, una API de REST.
Pueden hacer la misma llamada a la API de REST ustedes mismos. Esa es una forma de hacerlo. Otra forma es ir a la consola web así como creamos una instancia de Compute Engine. En vez de ir a la parte de la interfaz de usuario de Compute Engine se puede ir a la parte del almacenamiento de la interfaz de usuario. Pero, debido a que es una API de REST, también pueden usar Python o Java o el lenguaje que prefieran.
Cualquier lenguaje compatible con HTTP, que es prácticamente cualquier lenguaje puede interactuar con Cloud Storage mediante la API de REST. Por cierto, este es un tema muy común. Lo que se puede hacer con la línea de comandos se puede hacer con la API de REST, y como se puede hacer con esta API también se puede hacer con cualquier lenguaje. Lo que se hace desde una interfaz gráfica de usuario también usa la misma API de REST.
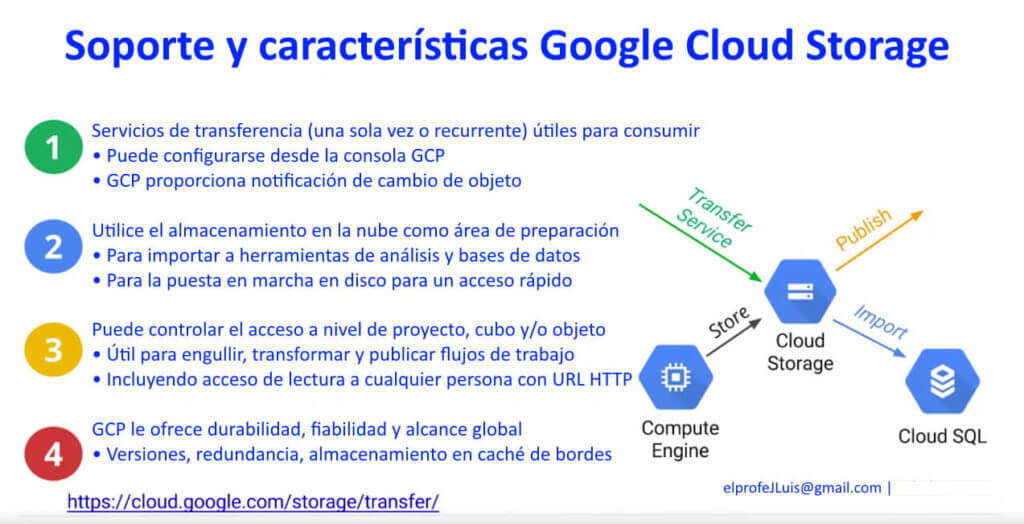
Además de usar la utilidad de GS para, de una sola vez tomar estos datos y copiarlos a la nube también pueden configurar un servicio de transferencia. El servicio de transferencia puede ser para una vez o puede ser recurrente. Pueden tomar los datos y transferirlos y, a medida que aparecen nuevos datos, pueden seguir transfiriéndolos.
La fuente de la transferencia puede ser la máquina local puede ser un centro de datos local, algo que es local puede ser AWS con depósitos S3 que pueden transferir, y pueden mantener el servicio de transferencia activo.
Ahora, como habíamos mencionado la idea de Cloud Storage es que se use como un área intermedia para importar datos a Cloud SQL, BigQuery y Dataproc o a diferentes herramientas de análisis y bases de datos.
También se puede usar para tomar los datos de Cloud Storage y moverlos a un disco SSD local en una VM de Compute Engine. Si realizarán lectura de datos de forma rutinaria todo el tiempo sería conveniente moverlos de Cloud Storage a un disco local. Una vez que los datos estén en Cloud Storage podrán controlar el acceso en ese nivel de objeto. Muchas veces tendrán objetos que estarán relacionados y estarán en la misma «estructura de carpetas» o en un nivel de depósito.
Entonces, se puede controlar el acceso en ese nivel de depósito pero cada depósito pertenece a un proyecto. Un proyecto es la forma en la que se hace la facturación en GCP. Cuando se crea un depósito en un proyecto se está indicando qué cuenta de facturación será responsable del pago del almacenamiento.
Se puede controlar el acceso en el nivel de proyecto. Por ejemplo, que las personas que tengan permisos de editor en este proyecto también pueden agregar y quitar archivos en ese depósito en particular. Pero una de las tareas cruciales de control de acceso que pueden realizar es usar control de acceso para todos los usuarios autenticados.
En otras palabras, se puede dar acceso a cualquier usuario que acceda con su cuenta de Google. La otra manera de hacerlo es dar acceso a todos los usuarios. Esto significa que ni siquiera se necesita acceder para obtener los datos disponibles.
Pueden obtenerlos mediante la URL HTTP
¿Por qué querrían hacer eso?
¿Se acuerdan de lo que les dije acerca de GCP?
Dije que una vez que colocan información en Cloud Storage es durable y persistente está almacenada en caché perimetral, tiene copias múltiples. En otras palabras, es una manera fácil de tener una red de entrega de contenido para los datos. Solo tomen los datos, los datos estáticos, súbanlos a GCS y proporcionen a las personas la URL de esa ubicación en GCS. Google Cloud se encarga del almacenamiento en caché perimetral la replicación, la confiabilidad, la durabilidad y todo lo demás.
Si van a poner sus datos en la nube incluso si están creando instancias de Compute Engine para procesar datos en la nube deberían tener una idea clara de qué zona o región es más conveniente.
¿Qué es una zona? ¿Qué es una región?
Es una organización geográfica. Pueden pensar en una zona como en un centro de datos. Es conveniente escoger la zona o región más cercana a sus usuarios. Y esto es para reducir la latencia.
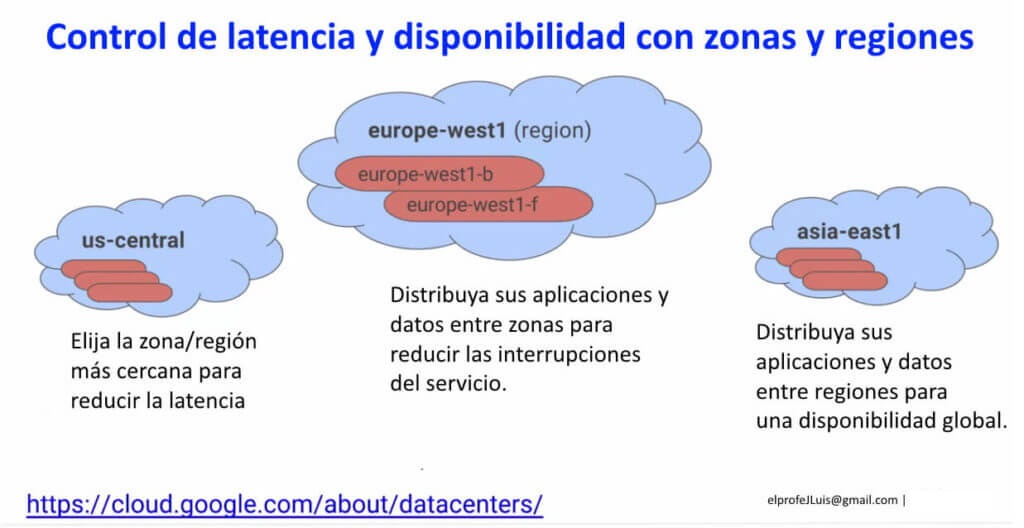
Si la mayoría de sus usuarios están en la parte central de EE.UU. deberían escoger el centro de datos en Iowa y usar «us-central» la zona y la región más apropiadas para reducir la latencia.
Pero el problema con tener todo en una zona es, ¿qué sucede si esa zona falla? Si un tornado afecta a Iowa y no se puede acceder al centro de datos tampoco se podrá acceder a sus aplicaciones.
Entonces, para limitar las interrupciones del servicio sería conveniente tener múltiples zonas dentro de la misma región. Por ejemplo, pueden ejecutar la aplicación en la zona «b» y la zona «f» donde la zona «f» actúa como respaldo de la zona b, por ejemplo. La distribución de los datos ausentes en varias zonas es una forma de reducir las interrupciones del servicio. Esto funciona si todos los usuarios están en Europa o si todos están en EE.UU.
Usarían «us-central» si todos están en EE.UU. y «europe-west» si todos están en la UE.
¿Qué pasa si tienen una aplicación global?
Se tiene una aplicación con algunos usuarios en Japón, otros en Europa y otros en EE.UU. Si ese fuera el caso, entonces necesitarán distribuir las apps y los datos no solamente dentro de una región sino en todas las regiones. Esto es para que sus aplicaciones estén disponibles globalmente.
En resumen podemos controlar la latencia mediante la zona o región más cercana podemos usar múltiples zonas en una región para minimizar las interrupciones y podemos usar regiones múltiples para proporcionar acceso global a la aplicación.
